pythonで自動化 ~PyAutoGUIで画像翻訳の自動化~

昔大学の先輩がマウスなんか無くてもキーボードだけで十分みたいな話をしてくれたんですよね。
結局今でもマウス普通に使ってるわけですが、上記マインドでPyAutoGUIというライブラリを使いこなせばそれなりに自動化が出来るなと思い検討してみた。
やること
タイトルの通り、今回google翻訳で提供している画像翻訳機能を自動で行ってみます。
というのも一つ一つの画像は手動でやればいいのですが、たくさんの画像の翻訳をまとめてやりたいときに便利かなと。
google翻訳による画像翻訳
以下URLからアクセスすると、画像翻訳が出来るサイトへ飛びます。(クエリパラメータが重要)
画像アップロード後、「翻訳をダウンロード」ボタンを押せば簡単に翻訳後の画像をDL可能。
https://translate.google.co.jp/?hl=ja&tab=TT&sl=auto&tl=ja&op=images
Googleは、スクレイピングを利用規約で禁止
当初seleniumなんかでアクセスしようかとも思いましたが、Pythonで起動されたブラウザにおいては、Google関連サービスの操作は出来ないようになっているそうです。(Googleの規約により、そもそもwebスクレイピングが禁止されている)
そのため、今回は事前に手動でブラウザを起動しておき、起動しているブラウザに対してPyAutoGUIで自動的に操作させます。
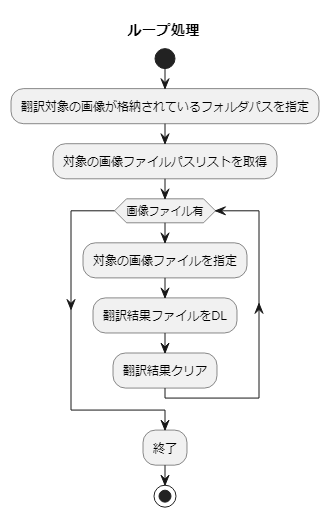
処理の流れ
前述の翻訳サイトにchromeブラウザでアクセスしたのち、画像翻訳に関する各種操作をPyAutoGUIで行います。
注意事項として、操作のスタート地点にブラウザ上のターゲットを合わせる必要があります。
簡単なフロー図は以下。
翻訳完了の判断
PyAutoGUIのライブラリには画像認識できる機能があり、本機能を使って翻訳の完了判断を行います。
具体的には翻訳中に画面上に出ている以下表示が無くなるまで待つような実装を行います。
2枚目、3枚目は翻訳後も存在しますが、翻訳結果の画像が画面に表示されることによって画面外に出ることを期待しておりそうならない場合はchromeブラウザの画面を事前にある程度拡大しておく必要があります。


ソース
以下実行コードになります。
実行前に必ずchromeブラウザで前述の翻訳サイトを開いておき、翻訳対象の画像が入っているフォルダ選択後はブラウザをクリックしておく必要があります。
また、前述の翻訳完了の判断に必要な画像をsrcと同じフォルダに配置しておいてください。
import pyautogui as pag
import time
import os
from tkinter import filedialog
import pyperclip
from natsort import natsorted
def main():
# フォルダパス取得
dirname = os.path.dirname(__file__)
iDir = os.path.abspath(dirname)
file_path = filedialog.askdirectory(initialdir=iDir)
# フォルダ内の画像パスリスト取得
file_list = os.listdir(file_path)
file_list = natsorted(os.listdir(file_path))
print(file_list)
# 起動済みのブラウザをクリック
time.sleep(3)
pag.press(['tab'])
pag.press(['tab'])
pag.press(['tab'])
pag.press(['tab'])
pag.press(['tab'])
pag.press(['tab'])
pag.press(['tab'])
pag.press(['tab'])
pag.press(['tab'])
pag.press(['tab'])
pag.press(['tab'])
pag.press(['tab'])
pag.press(['tab'])
pag.press(['tab'])
dl_file_num_old = 0
for file in file_list:
# 対象の画像ファイルを指定
pag.press('enter')
time.sleep(1)
# クリップボードへ文字列(画像ファイルへのパス)コピー
pic_path = file_path + "/" + file
print(pic_path)
pyperclip.copy(pic_path.replace("/","\\"))
with pag.hold('ctrl'):
pag.press(['v'])
pag.press('enter')
image = 'trance_chk1.png' # 認識したい画像のパス
while True:
location = pag.locateOnScreen(image, confidence=0.9) # confidenceは画像の一致度合い
if location is None: # 画像が検出されない場合、起動が終了したと判断
break
image = 'trance_chk2.png' # 認識したい画像のパス
while True:
location = pag.locateOnScreen(image, confidence=0.9) # confidenceは画像の一致度合い
if location is None: # 画像が検出されない場合、起動が終了したと判断
break
image = 'trance_chk3.png' # 認識したい画像のパス
while True:
location = pag.locateOnScreen(image, confidence=0.9) # confidenceは画像の一致度合い
if location is None: # 画像が検出されない場合、起動が終了したと判断
break
# 翻訳結果をDL
with pag.hold('shift'):
pag.press(['tab'])
with pag.hold('shift'):
pag.press(['tab'])
pag.press('enter')
pag.press(['tab'])
pag.press('enter')
time.sleep(1)
# ダウンロード結果の確認
dl_file_list = os.listdir("C:/Users/h1110/Downloads")# 自身のDLパスにする
dl_file_num = len(dl_file_list)
print(dl_file_num)
if dl_file_num <= dl_file_num_old:
print("翻訳終了")
break
else:
dl_file_num_old = dl_file_num
if __name__ == "__main__":
main()最後に
環境次第でタブの回数とかが変わってしまうのがネックですね。
もっと汎用的で使いやすいように作りたい。
