pythonでOCRを使用しドラッグ領域の翻訳 ~③OCRで指定座標の文章取得~

今回はいよいよpythonとOCRを使って文章の読み出しを行っていきます。
なお、OCRで読み取る座標情報の取得は以下記事のコード使用が前提となるため。事前に確認をお願いします。

処理概要
ツール全体における対象処理は以下の⑥~⑦となります。
① ツール起動
② 領域取得画面を表示
③ 翻訳開始ボタン押下
④ 翻訳領域取得 (複数領域を選択可能)
⑤ 領域取得画面を閉じる
⑥ 画像作成
⑦ OCRで画像から英文を抽出
⑧ 翻訳実施 (→選択した領域の数だけ⑥、⑦、⑧を繰り返す)
⑨ すべての翻訳結果を画面に表示する
事前準備
まずはオープンソースの OCR エンジンであるTesseractをインストールしましょう。
インストール方法は以下を参考にしてください。

ここで私はつまずいたのですが、上記インストール完了後には必ず環境変数の設定を行ってください。
設定内容は環境変数のPathに、Tesseractがインストールされているフォルダまでのパスを追加するだけです。
終わったらPython から OCR エンジンを利用可能にするためのモジュールであるPyOCRをインストールします。
pip install pyocrコード
import sys
import os
import pyocr
import pyocr.builders
import pyautogui
import cv2
from PIL import Image
import trim
TESSERACT_PATH = 'C:\Program Files\Tesseract-OCR'
TESSDATA_PATH = 'C:\Program Files\Tesseract-OCR\\tessdata'
os.environ["PATH"] += os.pathsep + TESSERACT_PATH
os.environ["TESSDATA_PREFIX"] = TESSDATA_PATH
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
# The tools are returned in the recommended order of usage
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
# Ex: Will use tool 'libtesseract'
langs = tool.get_available_languages()
print("Available languages: %s" % ", ".join(langs))
lang = langs[0]
print("Will use lang '%s'" % (lang))
# Ex: Will use lang 'fra'
# Note that languages are NOT sorted in any way. Please refer
# to the system locale settings for the default language
# to use.
# ↑PyOCR使う時の呪文、おまじない。
# スクリーンショット撮影 → グレースケール → 画像を拡大
def ScreenShot(x1, y1, x2, y2):
sc = pyautogui.screenshot(region=(x1, y1, x2, y2)) # PosGet関数で取得した座標を使用
sc.save('TransActor.jpg')
# あとは画像拡大してみましょうか グレースケールも有効? OpenCVにも頼ってみよう
img = cv2.imread('TransActor.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
tmp = cv2.resize(gray, (gray.shape[1]*2, gray.shape[0]*2), interpolation=cv2.INTER_LINEAR)
cv2.imwrite('TransActor.jpg', tmp)
# Image.openメソッドで画像が開かれる。PyOCRで文字認識、文字起こし
# 関数名は翻訳実装の名残
def TranslationActors():
txt = tool.image_to_string(
Image.open('TransActor.jpg'),
lang="eng", # 読み取る言語
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
# 読みやすいように整形
output_text = txt.replace('\n',' ').replace(' ',' ').replace(' ',' ').replace('.','.\n')
print("\n【原文】\n------------------------------------")
print(output_text)
print("------------------------------------")
'''
ここまでが文字認識→出力のゾーン
'''
# メイン処理 -
if __name__ == "__main__":
g_rtn_inf = trim.main()
for capture_inf in g_rtn_inf:
ScreenShot(capture_inf['start_x'],
capture_inf['start_y'],
capture_inf['end_x'] - capture_inf['start_x'],
capture_inf['end_y'] - capture_inf['start_y'])
TranslationActors()実施結果
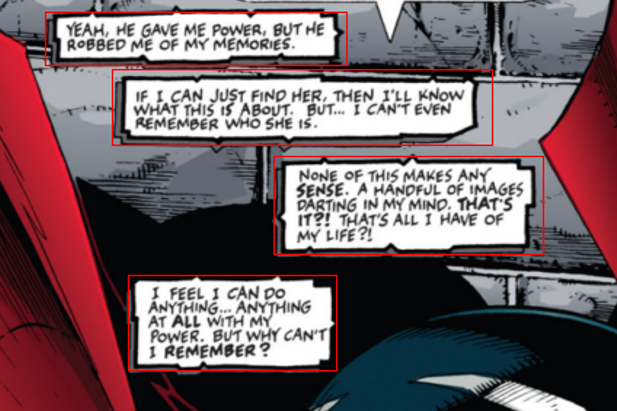
以下のように吹き出し部分をキャプチャした際の実施結果です。
文体が独特なこともあってうまく読み取れていない部分が見られます。
しかしながら大体読めればいいので今回はそれでも気にしません。
【原文】
------------------------------------
YEAH, HE GAVE ME Power, BUT HE ROBBED ME OF MY MEMORIES.
------------------------------------
【原文】
------------------------------------
‘a piece dale = a 1€ I CAN JUST FIND HER, THEN I'LL KNow WHAT THIS 1§ ABouUT.
BUT.
.
.
I CAN’TEVEN J.
REMEMBER WHO SHE IS.
------------------------------------
【原文】
------------------------------------
None OF THIS MAKES ANY, SENSE.
A HANDFUL OF IMAGES DARTING IN MY MINO.
THAT'S IT?! THAT'S ALL I HAVE OF My LIFE 2!
------------------------------------
【原文】
------------------------------------
I FEEL 1 CANDO ANYTHING.
.
.
ASS THING AT ALL WITH M PowEeR.
BUT WHY CAN‘T 1 REMEMBER?
------------------------------------参考サイト
今回は以下のサイトを参考に文章抽出を実施しました。
