pythonでOCRを使用しドラッグ領域の翻訳 ~④最終回、翻訳とツールの完成~

今回はいよいよ最終回としてツールを完成させたいと思います。
翻訳処理についてはpythonのgoogletransモジュールで簡単にできるのでこちらについても取り上げます。
処理概要
今回の対象処理は以下の①、⑧、⑨となります。
① ツール起動
② 領域取得画面を表示
③ 翻訳開始ボタン押下
④ 翻訳領域取得 (複数領域を選択可能)
⑤ 領域取得画面を閉じる
⑥ 画像作成
⑦ OCRで画像から英文を抽出
⑧ 翻訳実施 (→選択した領域の数だけ⑥、⑦、⑧を繰り返す)
⑨ すべての翻訳結果を画面に表示する
事前準備
googletransはGoogle 翻訳を利用することが出来るモジュールです。
Google 翻訳自体は皆さんもご存じの、左側のボックスにテキストを入れると、自動的に右側に翻訳文を表示してくれるブラウザの機能で、私も時々お世話になっております。
本モジュールを使えば以下のような簡単なコードで同様の翻訳結果を得ることが出来ます。
from googletrans import Translator
trans_data = "Hello world."
def translation(trans_data):
tr = Translator()
result = tr.translate(trans_data, src="en", dest="ja").text
print(result)通常「pip install googletrans」でインストールすればよいのですが、実行してみると以下のようなエラーが発生し、私の環境ではうまく動きませんでした。
AttributeError: 'NoneType’ object has no attribute 'group’
デフォルトでバージョン3.0.0がインストールされていたのですがなんでもバージョンが4.0.0-rc1以上(現在はPRE-RELEASE 版)でないと正常に動かない場合があるらしいです。
インストール時は以下コマンドで実施してください。
pip install googletrans==4.0.0-rc1コード
コード全体は以下にあるので引っ張ってきてください。

以下はメインのGUIと翻訳処理のコードになります。OCRや領域取得については過去記事を参照してください。
# coding: utf -8
import PySimpleGUI as sg # ライブラリの読み込み
from googletrans import Translator
import trim
import ocr
# テーマの設定
# sg.theme("Dark Blue 3 ")
L1 = [
[sg.Button("実行", border_width=4, size=(30, 2), key="trans_start")]
]
L2 = [
# 翻訳前
[sg.Multiline(default_text="",
text_color="#000000",
background_color="#ffffff",
size=(80, 50),
key="-INPUT_TXT-")]
]
L3 = [
# 翻訳後
[sg.Multiline(default_text="",
text_color="#000000",
# background_color="#ffff00",
size=(80, 50),
key="-OUTPUT_TXT-")]
]
L = [[sg.Frame("翻訳処理の開始",L1)],
[sg.Frame("翻訳前",L2),sg.Frame("翻訳後",L3)]]
# ウィンドウ作成
window = sg.Window("AES_TOOL ", L)
def main():
# イベントループ
while True:
# イベントの読み取り(イベント待ち)
event, values = window.read()
all_input_txt = ""
all_output_txt = ""
if event == "trans_start":
# ドラッグ領域の取得
rtn_inf = trim.main()
print("終了")
for i , capture_inf in enumerate(rtn_inf):
# ドラッグした領域の数だけキャプチャ、文字抽出
ocr.ScreenShot(capture_inf['start_x'],
capture_inf['start_y'],
capture_inf['end_x'] - capture_inf['start_x'],
capture_inf['end_y'] - capture_inf['start_y'])
# 抽出した文字列の翻訳
input_txt = ocr.TranslationActors()
output_txt = translation(input_txt)
# 出力データ更新
all_input_txt += "/* ドラッグ領域(" + str(i + 1) + ") */\n" + input_txt + "\n\n"
all_output_txt += "/* ドラッグ領域(" + str(i + 1) + ") */\n" + output_txt + "\n\n"
# 画面上の表示を更新
window["-INPUT_TXT-"].Update(all_input_txt)
window["-OUTPUT_TXT-"].Update(all_output_txt)
# 終了条件( None: クローズボタン)
elif event is None:
break
# 終了処理
window.close()
def translation(trans_data):
tr = Translator()
result = tr.translate(trans_data, src="en", dest="ja").text
return result
if __name__ == "__main__":
main()実行結果
main.pyを起動すると以下のような画面が出力されます。

実行ボタンを入力し、ドラッグ画面を出力されます。翻訳したい領域を指定後は×ボタンを入力することでOCR領域の指定を終了します。
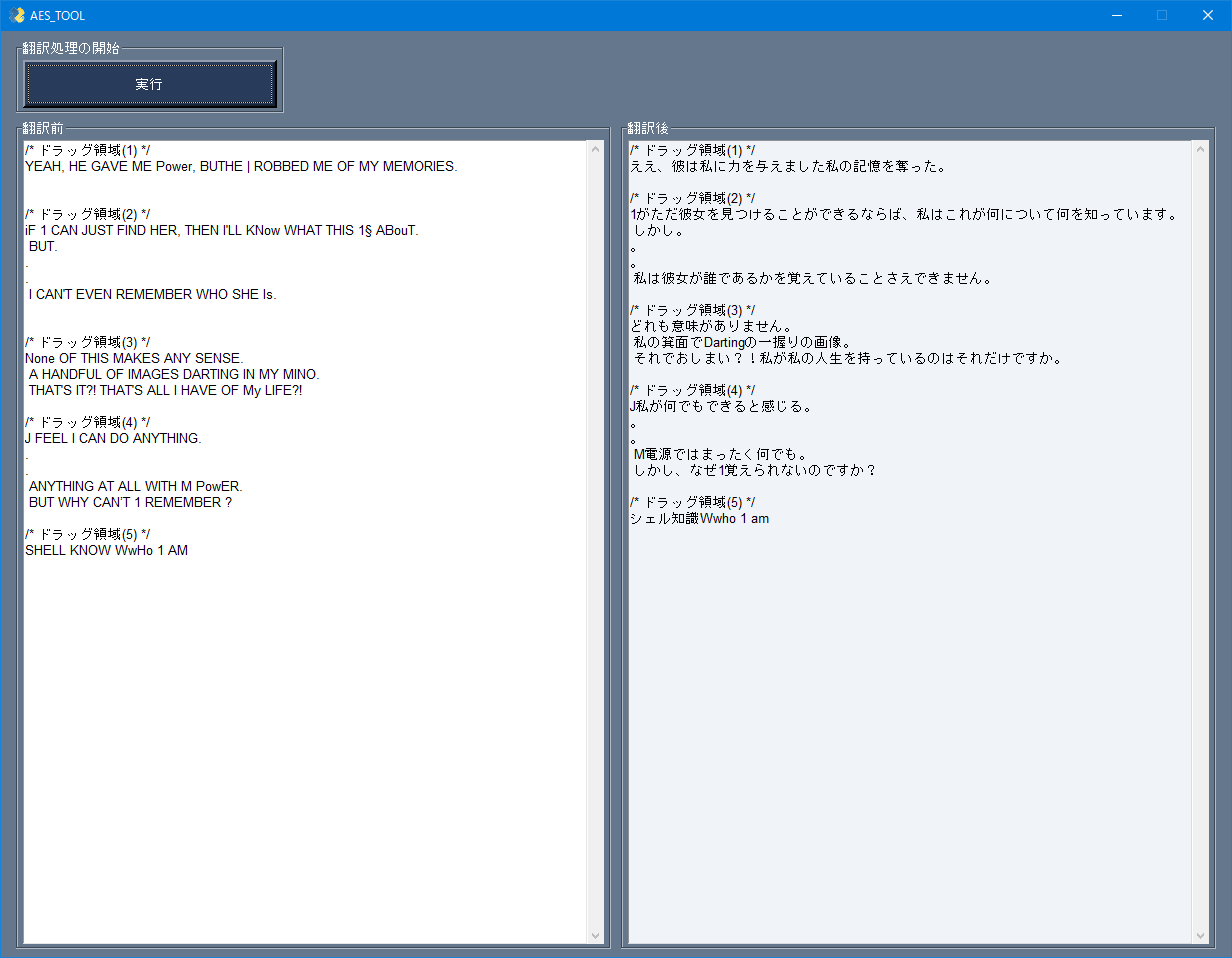
しばらくすると以下のような翻訳結果が出力されます。
最後に
作っては見たものの翻訳内容の質の悪さに愕然としました。
もしかしたらフォントがもっとしっかりしている文章の読み取りであればもう少し読める文章を出力してくれるかもしれません。
正直いちいちドラッグするのもめんどくさいので、結局英語を勉強した方がいいかもしれません。あるいはコメント領域をツールが検知してドラッグする必要すらなくすか。
その他機能拡張として英語→日本語以外の翻訳をユーザが指定できるようにしたりするとより使い勝手は上がるかな。
いずれにせよ課題はまだまだたくさんあると感じました。