pythonのopen関数を理解する ~応用編:関数ヘッダの置き換え~

前回open関数の基本について確認しましたが、今回は実際に関数ヘッダの置換という具体的な用途に対してpythonとopen関数を活用していきます。
前回の内容(open関数の基本)については以下参照。

はじめに
最近顧客から急にソースコードの各種ヘッダ情報を既存のものからDoxygenの記法に置き換えろとの要望が出てきました。
そこで工数削減の一環として、pythonを利用して既存の関数ヘッダを自動で置き換えられないか試してみます。
置き換え内容
会社のヘッダそのまま使うわけにもいかないので、以下のそれっぽい関数ヘッダを置き換えていきます。
//------------------------------------------------
// メモリ領域をコピーする
//------------------------------------------------
// 関数名:memcpy
//------------------------------------------------
// 概要:メモリ領域srtの先頭sizeバイトをメモリ領域dstへコピーする。
// 引数:dst コピー先のメモリ領域
// src コピー元のメモリ領域
// size コピーするバイト数
// 戻り値:dstへのポインタ
// 注意事項:コピー先とコピー元の領域が重なる場合はmemmoveを使用すること
//------------------------------------------------
void* memcpy(void *restrict dst, const void *restrict src , size_t size)
{
return;
}置き換え後のDoxygenフォーマットイメージは以下。
/**
* メモリ領域をコピーする
*
* メモリ領域srtの先頭sizeバイトをメモリ領域dstへコピーする。
* @param dst コピー先のメモリ領域
* @param src コピー元のメモリ領域
* @param size コピーするバイト数
* @return dstへのポインタ
* @attention コピー先とコピー元の領域が重なる場合は
* memmoveを使用すること
*/
void* memcpy(void *restrict dst, const void *restrict src , size_t size)
{
}ちなみにDoxygen使って上記を出力させるとこんな感じ。
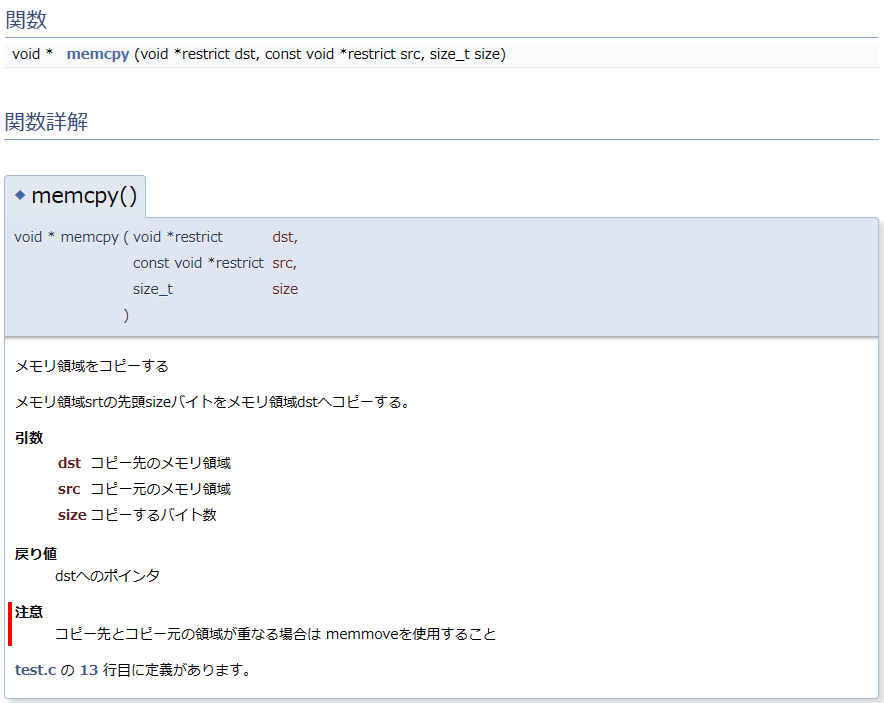
Doxygen向けの関数ヘッダのベースは以下を参考にさせていただきました。

ソース
思ったより長くなった。
読み出したファイルをそのまま置換したいときは、37行目の書き込みファイル名を同じにしてください。
# -*- coding: utf-8 -*-
import pprint
# 検索状態
SERCH_STATUS_NORMAL = 0
SERCH_STATUS_START = 1
def main():
# ファイル読み出し
read_lines = []
with open("sample.c", "r") as f:
read_lines = f.readlines()
# 関数ヘッダ置き換え
search_status = SERCH_STATUS_NORMAL
new_lines = []
header_lines = []
for read_line in (read_lines):
# 関数ヘッダ検索
if search_status == SERCH_STATUS_NORMAL:
if "//-----------" in read_line:
search_status = SERCH_STATUS_START
else:
new_lines.append(read_line)
# 関数ヘッダ取得
if search_status == SERCH_STATUS_START:
if "//" not in read_line:
search_status = SERCH_STATUS_NORMAL
# 関数ヘッダ挿入
new_header_lines = replace_header(header_lines)
new_lines.extend(new_header_lines)
new_lines.append(read_line)
header_lines = []
else:
header_lines.append(read_line)
# ファイル書き込み
with open("new_sample.c", "w") as f:
f.writelines(new_lines)
return
# ヘッダ情報の変換処理
def replace_header(header_lines):
new_header_lines = []
# 概略取得
new_header_info = get_header_info(header_lines,"// ","//------------------------------------------------")
new_header_lines.append( "/**\n")
new_header_lines.append( " * " + new_header_info[0])
if 1 < len(new_header_info):
for cnt in range(len(new_header_info)-1):
new_header_lines.append( " * " + new_header_info[cnt+1])
new_header_lines.append( " *\n")
# 概要取得
new_header_info = get_header_info(header_lines,"// 概要:","// 引数:")
new_header_lines.append( " * " + new_header_info[0])
if 1 < len(new_header_info):
for cnt in range(len(new_header_info)-1):
new_header_lines.append( " * " + new_header_info[cnt+1])
# 引数取得
new_header_info = get_header_info(header_lines,"// 引数:","// 戻り値:")
for cnt in range(len(new_header_info)):
new_header_lines.append( " * @param " + new_header_info[cnt])
# 戻り値取得
new_header_info = get_header_info(header_lines,"// 戻り値:","// 注意事項:")
new_header_lines.append( " * @return " + new_header_info[0])
# 注意事項取得
new_header_info = get_header_info(header_lines,"// 注意事項:","//------------------------------------------------")
new_header_lines.append( " * @attention " + new_header_info[0])
if 1 < len(new_header_info):
for cnt in range(len(new_header_info)-1):
new_header_lines.append( " * " + new_header_info[cnt+1])
new_header_lines.append( " */\n")
# 確認
print("置換前")
pprint.pprint(header_lines)
print("置換後")
pprint.pprint(new_header_lines)
return new_header_lines
# ヘッダ情報取得
def get_header_info(header_lines,serch_start_item,serch_end_item):
search_status = SERCH_STATUS_NORMAL
header_info = []
for header_line in header_lines:
if search_status == SERCH_STATUS_NORMAL:
if serch_start_item in header_line:
search_status = SERCH_STATUS_START
header_info.append(header_line.replace(serch_start_item,""))
else:
if serch_end_item in header_line:
break
else:
header_info.append(header_line.replace("//","").replace(" ",""))
return header_info
if __name__ == "__main__":
main()