pythonでGCP(Google Cloud Platform) ~webスクレイピングの定期実行~

今回はGCP(Google Cloud Platform)を利用してpythonのwebスクレイピングコードを定期実行させたいと思います。
なお、スクレイピング結果はスプレッドシートに適時情報を反映させます。
本記事は以下過去記事からの続きとなっております。


概要
なにぶん私も初心者なものであまり適切な解説はできていないと思いますがご了承ください。また、GCPの登録やプロジェクト作成済みの前提で進めていきます。
主にやったことは以下の通り。
- GCF(Google Cloud Functions)向けのseleniumを使用したスクレイピングコード作成
- SDK(Google Cloud SDK)を使用し作成したGCFプロジェクトにローカルのソースファイルをデプロイ
- Cloud Schedulerでトリガを1時間おきに実施するように設定
事前準備
Google Cloud SDKをインストール
ローカル上に用意したソースファイルのアップロードや、GCF(Google Cloud Functions)のデプロイなどに使います。
ファイルのアップロード方法についてはいくつかやり方があるのですが、SDKを使う方法が一番やりやすかったです。
デプロイはGUIでもできますが、慣れるとCUIのほうが早いです。
SDKのインストールについては以下参考に簡単にできます。

Selenum実行ファイルをダウンロード
クラウド上でSeleniumを動作させるために、ソースと一緒にドライバなどをクラウドへアップロードする必要があります。
以下から事前に必要ファイルをダウンロードしてください。
必要なのは「chromedriver」と「headless-chromium」の二つのみで、selenium_chrome/pack.zipのzipの中に入っています。

上記利用したスクレイピングコードについては、以下参考にしました。

トリガーの準備
ソースコードのデプロイ前に、Cloud Schedulerでトリガーを事前に用意しておく必要があります。
そんなに難しくなかったので説明は割愛。
コード
フォルダ構成
jsonファイルはスプレッドシートへアクセスするための鍵情報です。
ライブラリ
ライブラリ指定ファイル(requirements.txt)の設定は以下。
# Function dependencies, for example:
# package>=version
gspread>=5.2.0
pandas>=1.2.2
oauth2client>=4.1.3
google-cloud-error-reporting==0.30.0
selenium==3.141.0
setuptoolsソース
import time
import pytz
import os
import shutil
import stat
from pathlib import Path
from selenium import webdriver
import datetime
import pprint
import threading
from concurrent.futures import ThreadPoolExecutor
import gspread
import pandas as pd
from oauth2client.service_account import ServiceAccountCredentials
global driver
def add_execute_permission(path: Path, target: str = "u"):
"""Add `x` (`execute`) permission to specified targets."""
mode_map = {
"u": stat.S_IXUSR,
"g": stat.S_IXGRP,
"o": stat.S_IXOTH,
"a": stat.S_IXUSR | stat.S_IXGRP | stat.S_IXOTH,
}
mode = path.stat().st_mode
for t in target:
mode |= mode_map[t]
path.chmod(mode)
def settingDriver():
print("driver setting")
global driver
driverPath = "/tmp" + "/chromedriver"
headlessPath = "/tmp" + "/headless-chromium"
# copy and change permission
print("copy headless-chromium")
shutil.copyfile(os.getcwd() + "/headless-chromium", headlessPath)
add_execute_permission(Path(headlessPath), "ug")
print("copy chromedriver")
shutil.copyfile(os.getcwd() + "/chromedriver", driverPath)
add_execute_permission(Path(driverPath), "ug")
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--window-size=1280x1696")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--hide-scrollbars")
chrome_options.add_argument("--enable-logging")
chrome_options.add_argument("--log-level=0")
chrome_options.add_argument("--v=99")
chrome_options.add_argument("--single-process")
chrome_options.add_argument("--ignore-certificate-errors")
chrome_options.add_argument("--disable-dev-shm-usage")
chrome_options.binary_location = headlessPath
print("get driver")
driver = webdriver.Chrome(executable_path=driverPath, options=chrome_options)
# 評価総件数を取得
def get_num(path,total_num):
global driver
num_string = driver.find_element_by_xpath(path).get_attribute("aria-label")
percent_float = float((num_string).replace("点で評価したユーザーが","").replace("%います","")[1:])
num = total_num*(percent_float/100)
return round(num)
def scraping_main(url):
global driver
return_inf = {}
num_string = ""
driver.get(url)
time.sleep(1)
num_string = driver.find_element_by_xpath("//*[@id='__next']/div[1]/div/div/main/section[1]/div[3]/div/div[1]/div[1]/div[2]/p").text
# 未評価の場合はすべて0
if "未評価" == num_string:
print(4)
return_inf["総評価件数"] = 0
for i in range(5):
return_inf["星{}の評価件数".format(5-i)] = 0
else:
total_num = float((num_string).replace("/ ","").replace("件","").replace(",",""))
return_inf["総評価件数"] = round(total_num)
# 星ごとの評価総件数を取得
for i in range(5):
path = "//*[@id='__next']/div[1]/div/div/main/section[1]/div[3]/div/div[1]/div[2]/div/div[{}]/span[2]".format(i+1)
num = get_num(path,total_num)
return_inf["星{}の評価件数".format(5-i)] = num
print(return_inf)
return return_inf
SCOPES = ["https://spreadsheets.google.com/feeds","https://www.googleapis.com/auth/drive"]
SERVICE_ACCOOUNT_FILE = "movie-evaluation-344802-f41fbd96a6ce.json"
SPREADSHEET_KEY = "1uBhVPvfON09jvsQC7GzyCn5W4Uzqn5_OtkFhxRIHAb4"
def main(request1,request2):
settingDriver()
dt_now = datetime.datetime.now(pytz.timezone('Asia/Tokyo'))
credentials = ServiceAccountCredentials.from_json_keyfile_name(SERVICE_ACCOOUNT_FILE,SCOPES)
gs = gspread.authorize(credentials)
wb = gs.open_by_key(SPREADSHEET_KEY)
ws = wb.worksheet("映画一覧")
df = pd.DataFrame(ws.get_all_values())
df.columns = df.iloc[0]
df = df.drop(df.index[[0]])
# シート「映画一覧」の映画数だけ情報抽出
for index, row in df.iterrows():
# 該当の映画のシートが未作成の場合作成する
if wb.get_worksheet(index).title != row["映画タイトル"]:
# シート「ひな形」をコピーし新規シートにする
ws_base = wb.get_worksheet(-1)
wb.duplicate_sheet(source_sheet_id = ws_base.id, new_sheet_name = row["映画タイトル"],insert_sheet_index = index)
# スレッド処理で映画の評価情報取得
pool = ThreadPoolExecutor(max_workers=1)
future = pool.submit(scraping_main, row["URL"])
evaluation_inf = future.result()
pool.shutdown()
# 総評価件数が0以外(未評価でない)のときのみ、評価を反映させる
if 0 != evaluation_inf["総評価件数"]:
ws = wb.get_worksheet(index)
# 新規情報記入行の追加
ws.add_rows(1)
# スクレイピング結果反映
datas = []
datas.append(str(dt_now))
datas.append(evaluation_inf["総評価件数"])
datas.append(evaluation_inf["星5の評価件数"])
datas.append(evaluation_inf["星4の評価件数"])
datas.append(evaluation_inf["星3の評価件数"])
datas.append(evaluation_inf["星2の評価件数"])
datas.append(evaluation_inf["星1の評価件数"])
ws.append_row(datas)
print("driver quit")
driver.quit()つまずいたこと
ソースのアップロードが出来ない
ブラウザ上でGCFの設定をポチポチやっていたのですが、アップロードしたソースのデプロイが全然うまくいきませんでした。
(実はうまくいってたんだけどエラーで引っかかっていたというのもあるかもしれませんが。)
最終的にはSDKを使ってソースのアップロードとデプロイを実施しました。
コマンドオプションの詳細についてはGoogle Cloud SDKコマンドなんかで検索してみてください。
- SDK起動
- cdでソースファイルが格納されているフォルダへ移動
- 以下のようなコマンドでデプロイ
gcloud functions deploy movie_evaluation
--entry-point main
--runtime python39
--region asia-northeast1
--trigger-topic=hourlate
--allow-unauthenticated
--memory 1GBエラーの原因がわからない
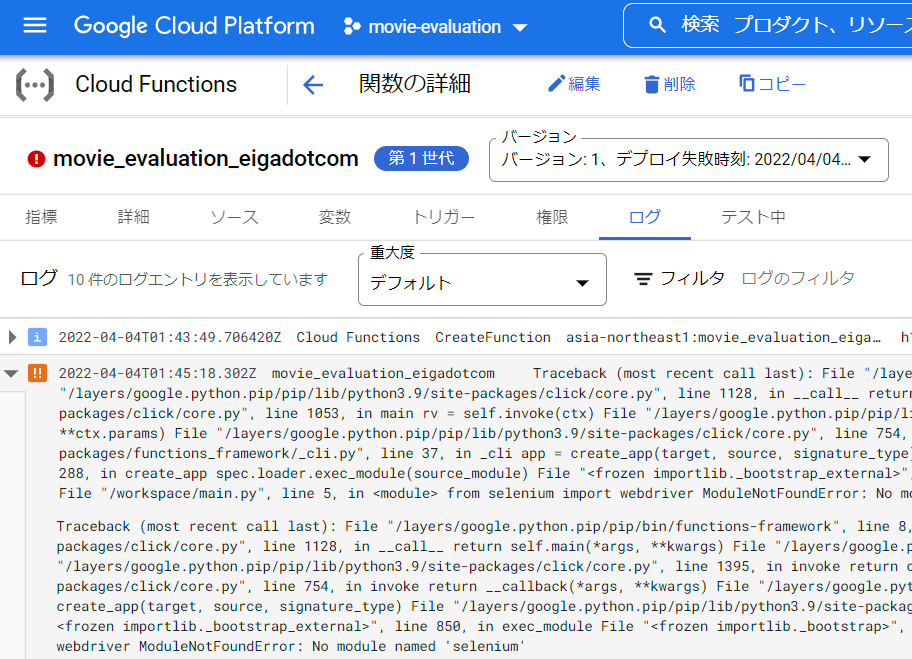
こちらGCFのログでちゃんと確認することが出来ました。print文も全部見れるんですね。(画像は後日取得)
find_elementがつかえない
find_element_by_xpath使用箇所にて、以下のようなエラーが発生しておりました。
AttributeError: 'dict’ object has no attribute 'text’
なんてことはないライブラリのverによって使い方が変わってるらしいのですが、クラウド上で実行することによって起きるエラーということでなかなか原因解明に苦労しました。
解決策は以下参考にseleniumのverを3.141.0に指定したら発生しなくなりました。

mainの引数が2つ
参考サイトでは引数が一つだったのですが、指定するpythonのバージョンによって引数の数が変わるらしいです。
今回使用したpython3.9では二つの引数をmain関数に持たせる必要がありました。なお、引数を使用する必要はありません。
メモリエラー
初めに実行したとき、以下のログが出力され動作しませんでした。
Function invocation was interrupted. Error: memory limit exceeded
こちらは使用メモリを216MB(デフォルト) → 512MBに変更することで解決しました。
ちょっとスクレイピングとスプレッドシート更新しただけでそんなにメモリ食うのは不思議ですが。今後処理が増えることも考慮して1GBにしてみました。
トリガーの時刻設定
ちゃんと書いてある説明を読めという話ですが、慣れない表記で少し戸惑いました。
1時間おきに実行したい場合は以下を使用。
0 */1 * * *そうするとちゃんと実行間隔が1時間おきになってくれる。

pythonコードの標準時刻
日本時間になっていなかったので以下のようにする必要がありました。
import pytz
dt_now = datetime.datetime.now(pytz.timezone('Asia/Tokyo'))タイムアウトの発生
映画の数を15個にしてみたところ、処理が途中で終了していました。ログを確認したら以下のようになっていました。
Function execution took 60004 ms, finished with status: 'timeout’
文字通り関数処理のタイムアウトが発生していたようです。とりあえずデフォルトの60秒から最大の540秒に設定して解決しましたが、メモリの件と合わせてどうも解せないですね。
最悪スレッド処理でどうとでもできますがメモリは大丈夫かな。
感想
現状狭く浅くという感じに、必要最低限のGCPによるpythonコード定期実行のノウハウを知ることはできたかと思います。
継続してGCPを利用する以上、お金の話もあるので引き続き勉強は頑張らなければ。
もちろん本来の目的である映画の評価情報の解析について、今回実行できた収集情報をもとにそのうち取り組んでいく予定です。