pythonでGCP(Google Cloud Platform) ~非同期処理の実行~

前回のpythonコードのデプロイ内容を生かしつつ、今回は別サイトのwebスクレイピングとスクレイピング結果のスプレッドシート反映処理をGCPで行いました。
対象の映画サイト(映画.com)へのスクレイピングや、スプレッドシート処理については以下過去記事にて取り上げておりますが、今回かなりリファクタリングが入っています。


処理概要
以下のような流れで処理を行います。
- 1時間おきにトリガ実行
- webdriver設定
- シート「映画一覧」からスクレイピング対象の映画情報を取得
- 各映画の評価反映シートを作成
- 各映画の最新レビューを更新
- 各映画のレビュー情報を抽出、集計
- 前回取得した時の最新レビューを検知したら、レビュー情報の抽出を終了する
- シート「映画一覧」に、今回スクレイピング時の最新レビューを書き込み
- 各映画シートに今回レビューのスクレイピング結果を反映(前回スクレイピング時の評価情報との合算値)
対象のスプレッドシートフォーマットは以下。
事前準備
トリガ設定
Cloud Schedulerで1時間おきに実行するように設定しました。
別のトリガと処理の実行タイミングを10分ずらすように設定(10 */1 * * *)しております。

構成
デプロイするフォルダの構成は以下のようになっております。
jsonファイルはスプレッドシートへアクセスするための鍵情報です。

chromedriverとheadless-chromiumの二つは以下のpack.zipから取得してください。

コード
ライブラリ
# Function dependencies, for example:
# package>=version
gspread>=5.2.0
pandas>=1.2.2
oauth2client>=4.1.3
google-cloud-error-reporting==0.30.0
selenium==3.141.0
setuptoolsメイン処理
import time
import pytz
import random
import os
import shutil
import stat
from pathlib import Path
from selenium import webdriver
import datetime
import pprint
import threading
from concurrent.futures import ThreadPoolExecutor
import gspread
import pandas as pd
from oauth2client.service_account import ServiceAccountCredentials
from selenium.common.exceptions import NoSuchElementException
SCOPES = ["https://spreadsheets.google.com/feeds","https://www.googleapis.com/auth/drive"]
SERVICE_ACCOOUNT_FILE = "movie-evaluation-344802-0f9f96a10567.json"
SPREADSHEET_KEY = "1uGvDp1pEL2Csd-r0gRzNgy-MJsZVMwZbULJtP6f7rLY"
dt_now = datetime.datetime.now(pytz.timezone('Asia/Tokyo'))
credentials = ServiceAccountCredentials.from_json_keyfile_name(SERVICE_ACCOOUNT_FILE,SCOPES)
# スプレッドシートにアクセス
gs = gspread.authorize(credentials)
wb = gs.open_by_key(SPREADSHEET_KEY)
# シート「映画一覧」から、収集元となる映画情報取得
ws = wb.worksheet("映画一覧")
df = pd.DataFrame(ws.get_all_values())
df.columns = df.iloc[0]
df = df.drop(df.index[[0]])
def add_execute_permission(path: Path, target: str = "u"):
"""Add `x` (`execute`) permission to specified targets."""
mode_map = {
"u": stat.S_IXUSR,
"g": stat.S_IXGRP,
"o": stat.S_IXOTH,
"a": stat.S_IXUSR | stat.S_IXGRP | stat.S_IXOTH,
}
mode = path.stat().st_mode
for t in target:
mode |= mode_map[t]
path.chmod(mode)
driverPath = "/tmp" + "/chromedriver"
headlessPath = "/tmp" + "/headless-chromium"
chrome_options = webdriver.ChromeOptions()
def settingDriver():
print("driver setting")
# copy and change permission
print("copy headless-chromium")
shutil.copyfile(os.getcwd() + "/headless-chromium", headlessPath)
add_execute_permission(Path(headlessPath), "ug")
print("copy chromedriver")
shutil.copyfile(os.getcwd() + "/chromedriver", driverPath)
add_execute_permission(Path(driverPath), "ug")
chrome_options.add_argument("--headless")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--window-size=1280x1696")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--hide-scrollbars")
chrome_options.add_argument("--enable-logging")
chrome_options.add_argument("--log-level=0")
chrome_options.add_argument("--v=99")
chrome_options.add_argument("--single-process")
chrome_options.add_argument("--ignore-certificate-errors")
chrome_options.add_argument("--disable-dev-shm-usage")
chrome_options.binary_location = headlessPath
return
# スクレイピング結果をスプレッドシートへ反映
def update_spread(review_inf,score_inf):
global wb
ws = wb.worksheet(review_inf["映画タイトル"])
datas = []
datas.append(str(dt_now))
datas.append(0)
values = list(score_inf.values())
# 初回は前回地との加算なし
if ws.row_count == 2:
# スクレイピング結果反映
for i ,value in enumerate(values):
datas.append(value)
datas[1] += value
ws.append_row(datas)
ws.add_rows(1)
else:
# スクレイピング結果反映
pre_datas = ws.row_values(ws.row_count-1)
for i ,value in enumerate(values):
pre_value = int(pre_datas[i+2])
datas.append(int(value) + pre_value)
datas[1] += int(value) + pre_value
ws.append_row(datas)
ws.add_rows(1)
# 最終取得レビュー更新) + int(ws.cell(write_row-1,))
ws = wb.worksheet("映画一覧")
row_cnt = 1
for index, row in df.iterrows():
row_cnt += 1
if row["映画タイトル"] == review_inf["映画タイトル"]:
ws.update_cell(row_cnt, 4, review_inf["最終レビュー"])
break
# スクレイピングによる評価件数取得
def scraping_main(url,get_review,title):
# 初期化
score_inf = {"0.0":0,"0.5":0,"1.0":0,"1.5":0,"2.0":0,"2.5":0,"3.0":0,"3.5":0,"4.0":0,"4.5":0,"5.0":0}
review_inf = {"映画タイトル": title,"最終レビュー": ""}
driver = webdriver.Chrome(executable_path=driverPath, options=chrome_options)
# 確認したい映画URLへアクセス
driver.get(url)
time.sleep(1)
# 未評価の場合はそのまま処理終了
try:
element = driver.find_element_by_css_selector(".total-number.icon-after.arrowopen")
except NoSuchElementException:
scraping_close(driver,review_inf,score_inf,"未評価1")
return review_inf
# 最新のレビュー情報を取得
try:
elements = driver.find_elements_by_class_name("user-review")
for element in elements:
if "pro" not in element.get_attribute("class"):
element = element.find_element_by_class_name("review-title")
if element.text != get_review:
review_inf["最終レビュー"] = element.text
break
else:
scraping_close(driver,review_inf,score_inf,"未評価2")
return review_inf
except NoSuchElementException:
scraping_close(driver,review_inf,score_inf,"未評価3")
return review_inf
# 全レビューページの取得
try:
for i in range(1,1000):
suspension_flg , score_inf = get_num(driver,get_review,score_inf)
if True == suspension_flg:
scraping_close(driver,review_inf,score_inf,"終了1")
break
else:
element = driver.find_element_by_partial_link_text("次へ")
scroll(driver)
element.click()
time.sleep(1)
except NoSuchElementException:
scraping_close(driver,review_inf,score_inf,"終了2")
pass
update_spread(review_inf,score_inf)
return review_inf
# スクレイピング処理を終了する
def scraping_close(driver,review_inf,score_inf,close_type):
driver.quit()
time.sleep(1)
print(review_inf)
print(score_inf)
print(close_type)
return
# ページ内を下までスクロール
def scroll(driver):
while 1:
html01=driver.page_source
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
html02=driver.page_source
if html01!=html02:
html01=html02
else:
break
# ページ内レビューの評価取得
def get_num(driver,get_review,score_inf):
suspension_flg = False
try:
elements = driver.find_elements_by_class_name("user-review")
for element in elements:
if "pro" not in element.get_attribute("class"):
element = element.find_element_by_class_name("review-title")
# 前回取得済みかどうかを判定
if get_review == element.text:
suspension_flg = True
break
else:
if "-" == element.text[0]:
score_inf["0.0"] += 1
else:
score_inf[element.text[:3]] += 1
except NoSuchElementException:
print("レビュー取得終了")
pass
return suspension_flg , score_inf
def main(request1,request2):
settingDriver()
# スレッド処理で映画の評価情報取得
futures = []
with ThreadPoolExecutor(max_workers=len(df), thread_name_prefix="thread") as pool:
# シート「映画一覧」の映画数だけ情報抽出
for index, row in df.iterrows():
# 該当の映画のシートが未作成の場合作成する
if wb.get_worksheet(index).title != row["映画タイトル"]:
# シート「ひな形」をコピーし新規シートにする
ws_base = wb.get_worksheet(-1)
wb.duplicate_sheet(source_sheet_id = ws_base.id, new_sheet_name = row["映画タイトル"],insert_sheet_index = index)
future = pool.submit(scraping_main,row["URL"],row["最終レビュー"],row["映画タイトル"])
futures.append(future)
time.sleep(0.001*random.randint(4, 2999))出力結果
出力結果は以下。
シート「映画一覧」については、D列が常に最新のレビューへと更新されます。

各映画シートについて、期待値が格納されていることも確認できました。
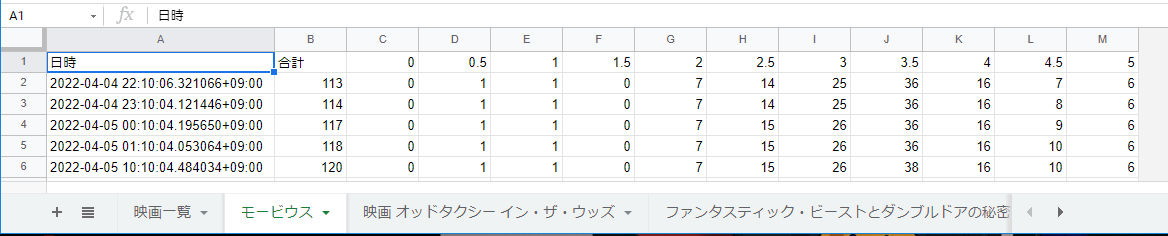
感想
実装していくうちにメモリリソースやアクセス上限、処理時間などを意識するようになり、リファクタリングを繰り返していたらかなり時間がかかってしまいました。
GCPのようなクラウドを利用する場合、本来の目的であるwebスクレイピングとは違う観点からコーディングをしていく必要があるのでなかなか難しさを感じております。
ですがクラウドはとても便利なので引き続き勉強をしていきたいと思います。